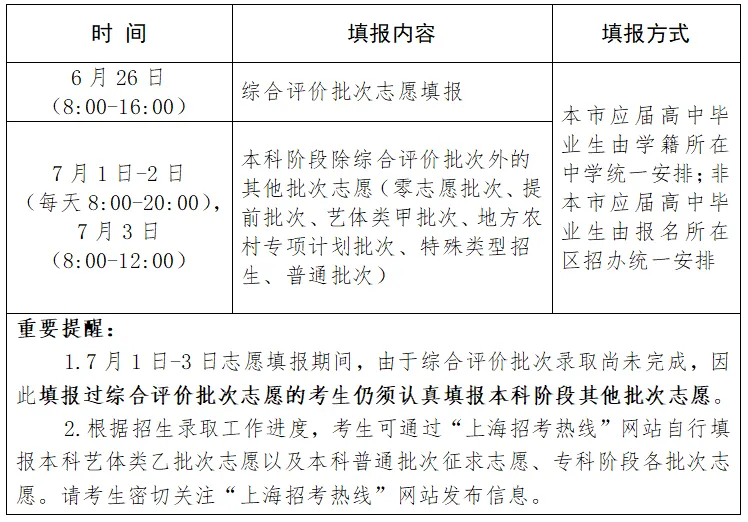
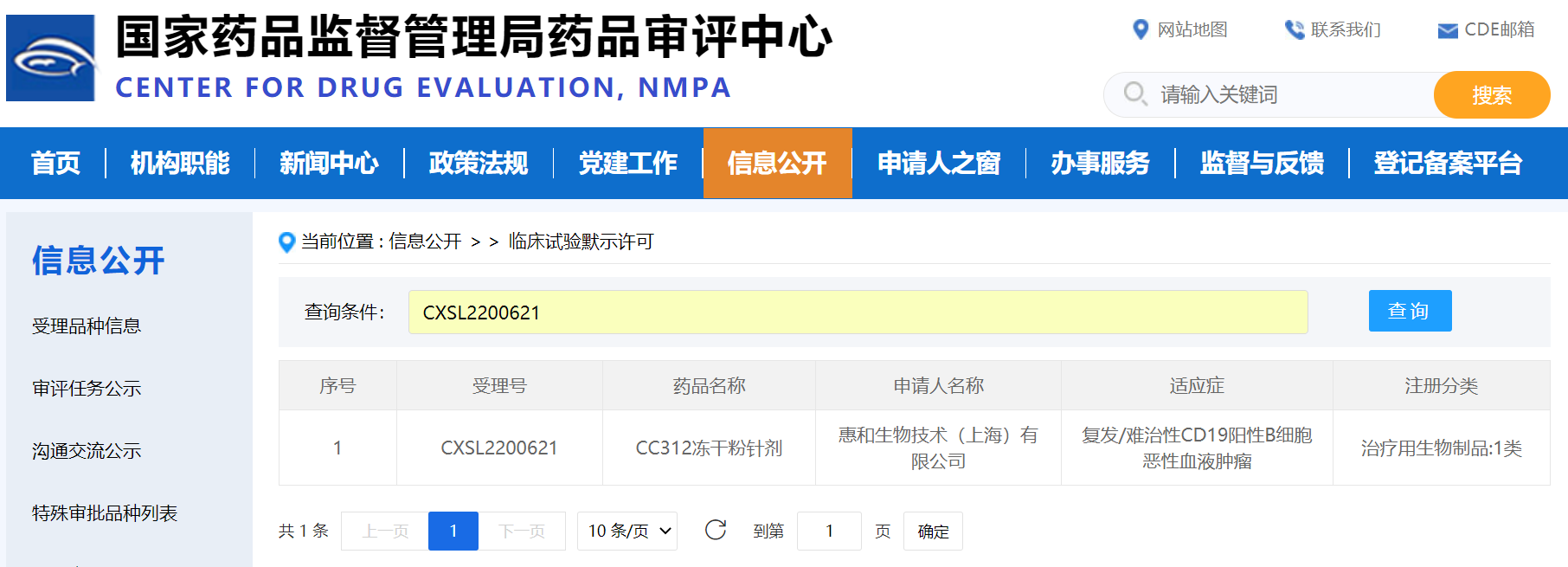
Users can apply for a trial, and the evaluation performance of the Shangtang big model exceeds that of the ChatGPT model | Language | Users
Shangtang Technology recently announced the results of its self-developed Chinese language model "SenseChat 2.0" on three authoritative language model evaluation benchmarks: MMLU, AGIEval, and C-Eval. The evaluation shows that "Shangliang" outperformed ChatGPT in all three test sets, achieving a breakthrough in the study of language models in China.
In April this year, Shangtang released the "Shangtang Nissin SenseNova" big model system and the Chinese language big model "SenseChat". At present, "discussion" has played a role in many industries and scenarios. For example, in scenarios that require a large amount of copywriting work, it can assist in processing various types of articles, reports, letters, product information, IT information, etc., editing, rewriting, summarizing, classifying, extracting information, producing Q&A, etc., effectively improving employee productivity. In customer service scenarios, it can also play many different corporate roles, such as bank customer service, picture book teachers telling stories to children, etc., and facilitate smooth communication and interaction to enhance customer experience.
It is reported that nearly a thousand corporate clients have applied for and experienced comprehensive abilities such as long text comprehension, logical reasoning, multiple rounds of dialogue, emotional analysis, content creation, and code generation through "negotiation". Users who want to apply for a trial of SenseChat 2.0 can log in to the website: https://lm_experience.sensetime.com/document/authentication .
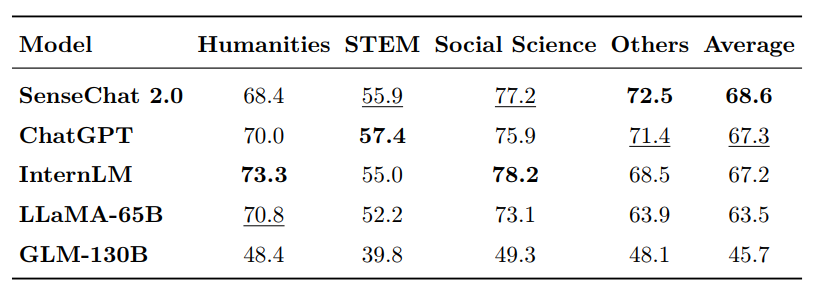
The scores of major language models on the three evaluation benchmarks of MMLU, AGIEval, and C-Eval
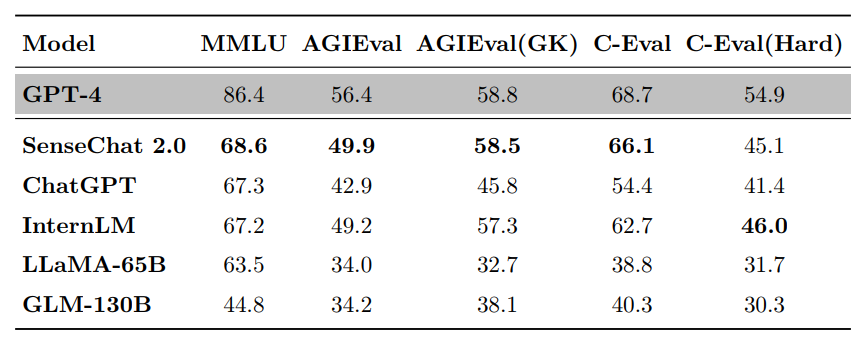
MMLU is a large-scale multitasking language comprehension evaluation benchmark jointly developed by the University of California, Berkeley, Columbia University, University of Chicago, and University of Illinois at Urbana Champaign. It covers 57 subjects in fields such as science, technology, engineering, humanities, and social sciences, with difficulty ranging from beginner level to advanced professional level, testing knowledge and problem-solving abilities.
In this review, the overall score of "negotiation" was 68.6, far exceeding the score of GLM-130B and also surpassing ChatGPT and LLaMA-65B, only lagging behind GPT-4 and ranking second.
The bold font in the figure indicates the best result, while the underline indicates the second best result.
AGIEval is released by Microsoft Research Institute and is specifically designed to evaluate the general abilities of basic models in tasks related to human cognition and problem-solving, in order to achieve a comparison between model intelligence and human intelligence. This benchmark selects 20 exams for human candidates, including university entrance exams, law entrance exams, mathematics competitions, lawyer qualification exams, national civil service exams, etc.
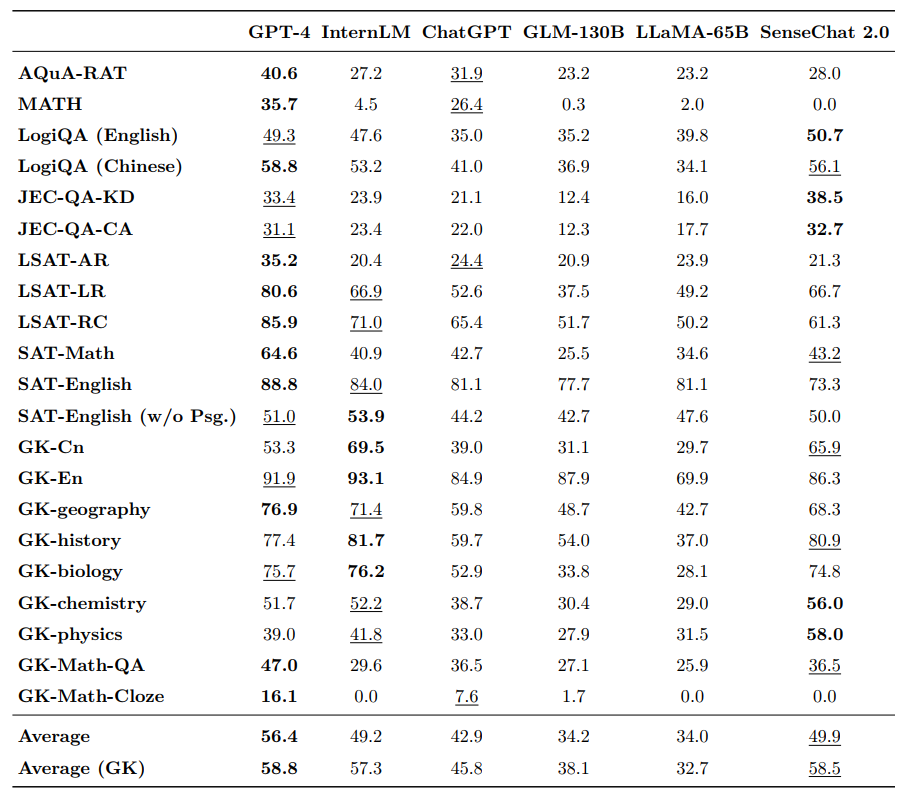
In this review, the "negotiation" score was 49.91, far ahead of GLM-130B, LLaMMA-65B, and also surpassing ChatGPT, second only to GPT-4. In the AGIEval evaluation subset, "Shangliang" ranked second with a score of 58.5, only slightly behind GPT-4.
The bold font in the figure indicates the best result, while the underline indicates the second best result.
C-Eval is a comprehensive exam evaluation set for Chinese language models, jointly constructed by Shanghai Jiao Tong University, Tsinghua University, and the University of Edinburgh. It includes 13948 multiple-choice questions, covering 52 different subjects and four difficulty levels.
In this evaluation, "Negotiate" scored 66.1 points, second only to GPT-4 among the 18 major models participating in the evaluation, and comprehensively leading major models such as ChatGPT, Claude, Bloom, GLM-130B, and LLaMA-65B. Among them, the C-Eval sub evaluation set selected 8 challenging subjects in mathematics, physics, and chemistry to assess the reasoning ability of large language models, and the performance of "negotiation" was also among the top.
Latest C-Eval Rankings
The Shangtang R&D team adopted a series of self-developed methods to enhance complex reasoning ability and a more effective feedback learning mechanism during the training phase, allowing large models to enhance their reasoning ability while reducing the hallucination problem of traditional large models.
It is reported that "Negotiate" also has a wide range of knowledge reserves, which can combine proprietary data of the enterprise's own industry to create a high-level knowledge base that meets the needs of the enterprise. It is also an AI code assistant that can implement the new "28/20 rule", which states that 80% of code is generated by AI and 20% is generated manually.