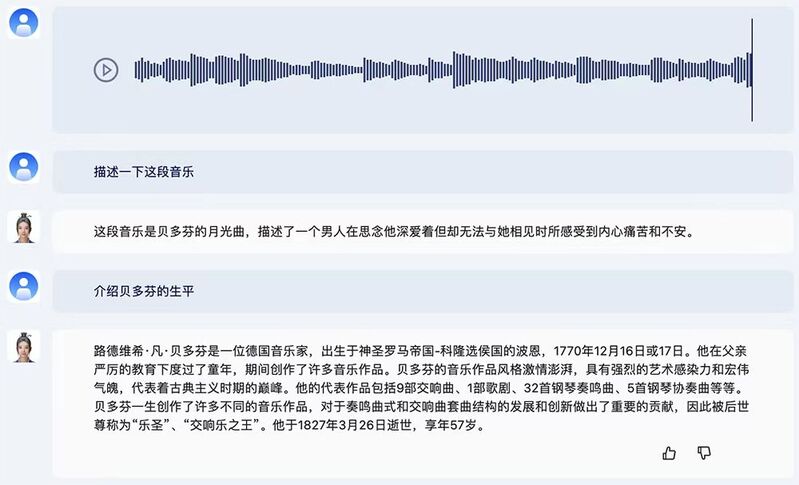
"Zidong Taichu" Full Modal Large Model Released, Precisely Positioned 3D Scene, Listening to "Moonlight Song" and Talking about Beethoven Images | Applications | Beethoven
Not only can you hear Beethoven talk freely in "Moonlight", but you can also achieve precise positioning in three-dimensional scenes, and complete scene analysis through the combination of images and sound. On June 16, at the AI Framework Ecological Summit, the Institute of Automation of the Chinese Academy of Sciences officially released the full mode large model of "Zidong Taichu".
This model is the 2.0 version upgraded from the 1.0 version of the 100 billion parameter multimodal model "Zidong Taichu". On the basis of voice, image and text three modes, it adds video, sensor signal, 3D point cloud and other modal data, breaks through the key technologies such as multimodal correlation for cognitive enhancement, and has full modal understanding, generation and correlation capabilities.
At the meeting, Xu Bo, the director of the Institute of Automation, presented in real-time for the first time the new features of the "Zidong Taichu" full modal cognitive model in music understanding and generation, three-dimensional scene navigation, signal understanding, multimodal dialogue, and invited on-site audiences to interact with the model in real-time.
Continuous Exploration from Multimodal to Full Modal
When humans perceive the world, they often involve information such as speech, images, and text simultaneously. Machines need to achieve higher levels of intelligence, just like humans, by developing larger models that connect more modalities such as graphics, text, and sound. Since 2019, the Institute of Automation has adhered to the core of "image audio text" multimodal technology, established a multimodal large model layout, integrated the advantageous resources of research directions such as images, text, and speech within the institute, carried out group style research, and successfully created the "Zidong Taichu" 1.0 multimodal large model in September 2021. "Zidong Taichu" 1.0 has propelled artificial intelligence from "one specialization and one capability" to "multiple specialties and multiple capabilities", taking a solid first step towards the development of universal artificial intelligence.
Entering the era of digital economy, the scope of data is constantly expanding, including not only human generated voice, image, text and other data, but also a large amount of structured and unstructured data generated by machines. In response to new demands and trends, "Zidong Taichu" 2.0 has achieved full modal open access to structured and unstructured data from a technical architecture perspective; Breaking through the multimodal grouping cognitive encoding and decoding technology that can fully understand and flexibly generate information, the multimodal cognitive ability of large models has been greatly improved.
From 1.0 to 2.0, the "Zidong Taichu" big model has broken through the interactive barriers of perception, cognition, and even decision-making, enabling artificial intelligence to further perceive and recognize the world, thereby extending more powerful universal capabilities.
[Broad prospects for industrial applications]
The "Zidong Taichu" 2.0 is based on the self-developed algorithm of the Institute of Automation, and is based on the Shengteng AI hardware and Shengsi MindSpore AI framework. With the support of the computing power of the Wuhan Artificial Intelligence Computing Center, it focuses on creating a full stack domestically produced universal artificial intelligence base.
At present, the "Zidong Taichu" model has shown broad industrial application prospects, and has begun a series of applications in fields such as neurosurgical surgical navigation, short video content review, legal consultation, medical multimodal differential diagnosis, and traffic violation image study.
In medical scenarios, the "Zidong Taichu" large model is deployed on the neurosurgical robot MicroNeuro, which can fuse multimodal information such as vision and touch in real-time during surgery, assisting doctors in real-time inference and judgment of surgical scenes. The research team is collaborating with Peking Union Medical College Hospital and utilizing the strong logical reasoning ability of "Zidong Taichu" to attempt breakthroughs in the diagnosis and treatment of rare human diseases.
Xu Bo stated that the Institute of Automation will continue to explore the integration of technology paths such as neuromorphic intelligence and game intelligence based on the "Zidong Taichu" model.