The domestically produced model "Scholar Puyu" achieved higher scores in the college entrance examination than ChatGPT language | Model | Puyu
As artificial intelligence big language models exhibit intelligence similar to that of humans, high difficulty and comprehensive exams are increasingly being introduced into language model evaluation. OpenAI tests the model's abilities through exams in various fields in the GPT-4 technical report. Today is the first day of the college entrance examination. Shanghai Artificial Intelligence Laboratory, Shangtang Technology, in collaboration with The Chinese University of Hong Kong, Fudan University, and Shanghai Jiao Tong University, released the "Scholar Puyu" parameter language model with a scale of billions. It has achieved better results than ChatGPT in multiple Chinese exams, including the Chinese college entrance examination.
"Shusheng Puyu" has 104 billion parameters and was trained on a high-quality multilingual dataset containing 1.6 trillion tokens. The comprehensive evaluation shows that this large model not only performs well in multiple testing tasks such as knowledge mastery, reading comprehension, mathematical reasoning, and multilingual translation, but also has strong comprehensive abilities, making it outstanding in comprehensive exams, including datasets of various subjects in the Chinese college entrance examination. The relevant technical report has been made public online, providing a detailed explanation of the technical characteristics and test results of the model.
The joint research and development team selected more than 20 evaluations to test "Shusheng Puyu", including the four most influential comprehensive exam evaluation sets in the world: the multi task exam evaluation set MMLU constructed by universities such as the University of California, Berkeley; AGIEval, a subject exam evaluation set launched by Microsoft Research Institute; The comprehensive exam evaluation set C-Eval for Chinese language models, jointly constructed by Shanghai Jiao Tong University, Tsinghua University, and the University of Edinburgh; The Gaokao Chinese College Entrance Examination (Gaokao) question evaluation set, constructed by a research team from Fudan University, includes various subjects as well as multiple question types such as multiple-choice, fill in the blank, and question answering.
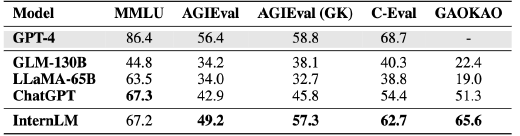
Comparison of performance of large models in four evaluation sets
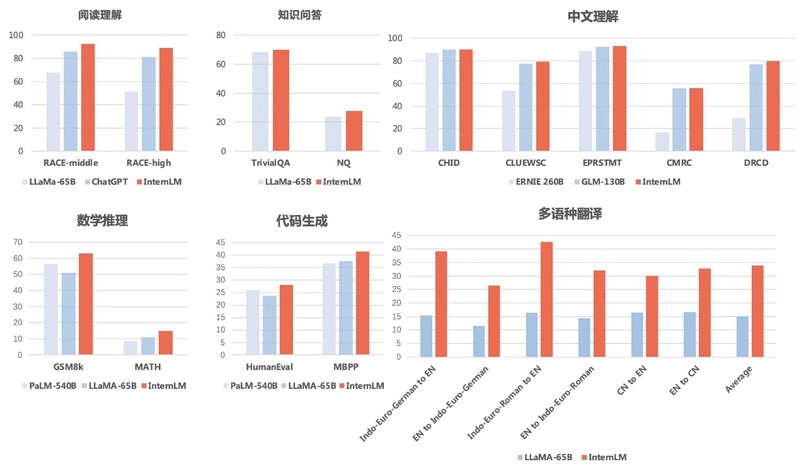
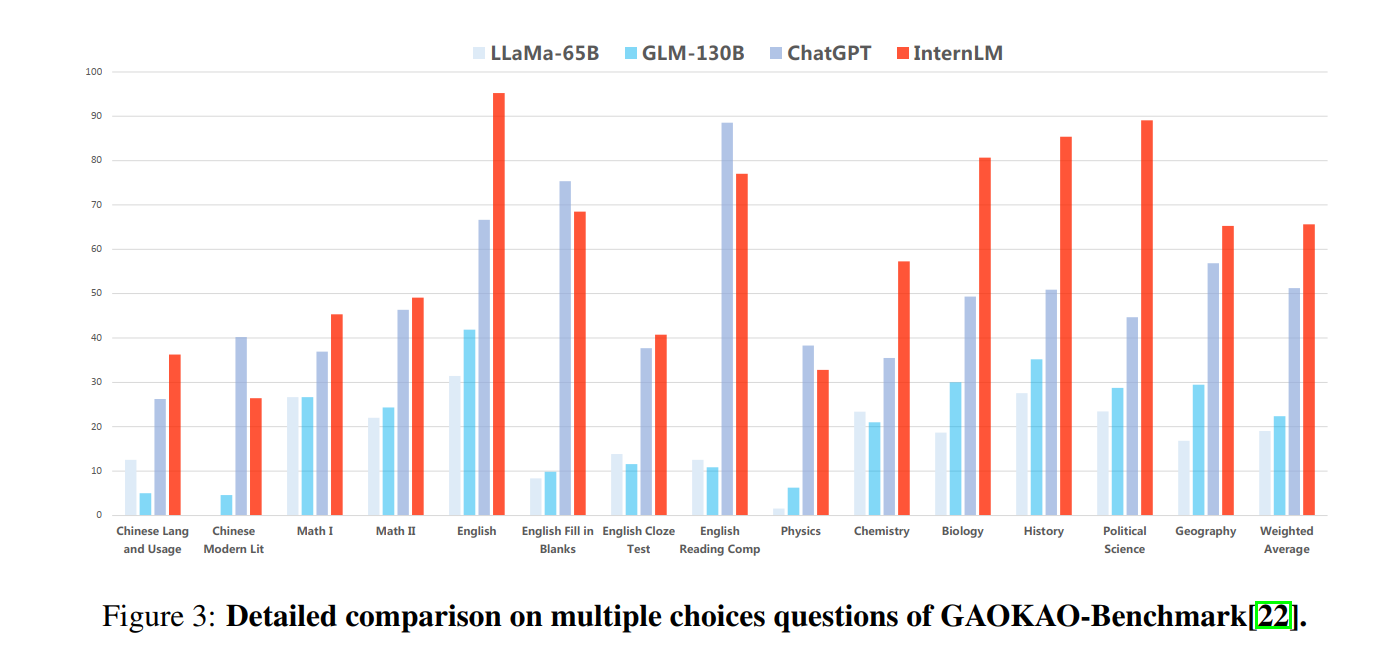
The exam results show that "Shusheng Puyu" not only significantly surpasses academic open source models such as GLM-130B and LLaMA-65B, but also surpasses ChatGPT in multiple comprehensive exams such as AGIEval, C-Eval, and Gaokao, and is on par with ChatGPT in MMLU, which is mainly based on American exams. Among them, "Shusheng Puyu" leads ChatGPT in over 75% of Gaokao's evaluation projects.
Comparison of Performance of Large Models in the Gaokao Evaluation Project
In order to avoid being biased towards science, researchers also evaluated and compared the sub item abilities of multiple language models through multiple academic evaluation sets. The results showed that "Shusheng Puyu" not only excelled in reading comprehension in both Chinese and English, but also achieved good results in evaluations of mathematical reasoning and programming abilities. The researchers also evaluated the security of the large model and found that Shusheng Puyu reached a leading level in both TrustfulQA and CrowS Pairs.
Comparison of evaluation of sub item abilities in large models
Although achieving excellent results in exam evaluations, the big language model still has many limitations in its abilities. It is reported that "Shusheng Puyu" is limited by a 2K contextual window length, and there are obvious limitations in understanding long texts, complex reasoning, coding, and mathematical logic deduction. In addition, during the dialogue process, large language models commonly suffer from hallucinations, conceptual confusion, and other issues. These limitations mean that there are still many issues to be overcome in the use of large language models in open scenarios.