Where is the "Hundred Model Battle" heading?, Domestic "Small Models" Officially Promoted for Open Source, Meta Hard Core OpenAI Hundred Model Battle | AI | Domestic
Since this year, the global Internet giants have launched a "100 model war", and Microsoft, Google, Baidu, Ali and others have successively ended. After more than half a year of competition, technology giants are facing a new round of competition around the big model ecosystem: facing the parameter "ceiling", will the future of big models be closed or open?
Open source models can run on home computers
On August 3rd, two open-source models, Qwen-7B and Qwen-7B Chat, were launched on the domestic AI developer community "Magic Build". They are the 7 billion parameter universal model and dialogue model of Alibaba Cloud Tongyi Qianwen, respectively. Both models are open source, free, and commercially available.
It is reported that Tongyi Qianwen Qwen-7B is a base model that supports multiple languages such as Chinese and English, and is trained on over 2 trillion token datasets. Qwen-7B Chat is a Chinese English dialogue model based on the base model, which has reached the cognitive level of humans. In short, the former is like a "foundation", while the latter is a "house" above the foundation.
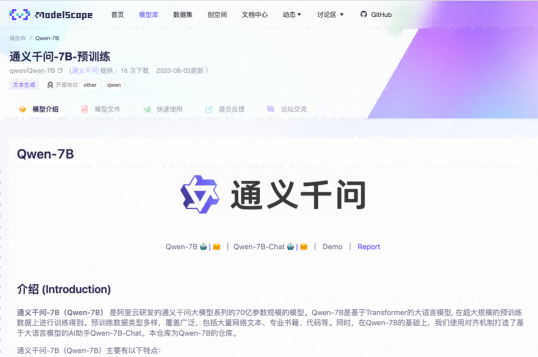
After actual testing, it has been shown that the Qwen-7B model performs well in terms of overall performance. Among them, on the English proficiency assessment benchmark MMLU, the scores are generally higher than mainstream models with the same parameter scale, and even surpass some models with parameter scales of 12 billion and 13 billion. On the Chinese evaluation C-Eval validation set, the model also achieved the highest score of the same scale. In terms of mathematical problem-solving ability evaluation GSM8K and code ability evaluation HumanEval, the Qwen-7B model also ranks among the top performers.
That is to say, in exams such as Chinese and English writing, math problem-solving, and coding, the Qwen-7B model is undoubtedly a "top student", with scores even exceeding those of international mainstream models at the same parameter level.
In addition, the industry is more concerned about the usability of the Qwen-7B model. As is well known, the training and operation of mainstream large models require specialized AI training chips. These chips are not only expensive, with each Nvidia A100 priced as high as $10000 to $15000, but are also monopolized by countries such as Europe and America, making it almost impossible to purchase them domestically. The domestically produced Qwen-7B model supports deployment on consumer grade graphics cards, which is equivalent to running the model on high-performance home computers.
Thanks to the free commercial use and low threshold, the launch of the Qwen-7B model has attracted the attention of AI developers. In just one day, on the code hosting platform GitHub, the Qwen-7B model has been starred and collected by over a thousand developers, with the vast majority of questioners being Chinese developers. As Alibaba Cloud stated in a statement, "Compared to the bustling AI open source ecosystem in the English speaking world, the Chinese community lacks an excellent foundation model. The addition of Tongyi Qianwen is expected to provide more choices for the open source community and promote the construction of China's AI open source ecosystem."
Open source or closed source
In fact, the Qwen-7B model is not the first big open source model. In fact, the "predecessor" GPT-2 of ChatGPT is also completely open source. Its code and framework can be used for free on the Internet, and related papers can be consulted. After ChatGPT became popular worldwide, OpenAI chose closed source development, and model codes such as GPT-3 and GPT-4 have become commercial secrets of OpenAI.
The so-called open source refers to open source code. For example, once a large model is announced as open source, within the scope of copyright restrictions, anyone can publicly access the model source code, make modifications, or even redevelop it. To put it simply, the source code is like a draft of a painting, and everyone can create their own artistic works by coloring according to the draft.
Closed source and open source are exactly the opposite. Only the source code owner has the power to modify the code, and others cannot obtain the "draft" and can only purchase the finished product from the software developer.
The advantages and disadvantages of open source and closed source are very obvious. The open source of large models will undoubtedly attract more developers, and the applications of large models will become more diverse. However, corresponding regulation and commercialization will become difficult, and it is easy to encounter the embarrassing situation of "making wedding dresses for others". After all, open source considers ecological co prosperity, and it is difficult to calculate how much money can be earned at this stage, and these challenges happen to be opportunities for closed source.
Open source or closed source is a life or death question for big models, and international giants have given the answer.
Facebook's parent company Meta released the large model Llama2 last month, which is open source and free for developers and business partners to use. OpenAI, on the other hand, has firmly chosen GPT-4 closed source development, which not only maintains OpenAI's leading position in the generative AI industry, but also earns more revenue. According to the authoritative magazine Fast Company, OpenAI's revenue in 2023 is expected to reach $200 million, including API data interface services and chatbot subscription service fees.
Domestic big models are also gradually going their separate ways. Alibaba Cloud's Tongyi big model was announced to be open to enterprises as early as April this year, and the open source of the Qwen-7B model will go further on the path of openness. Baidu's ERNIE Bot also recently announced that it will gradually open the plug-in ecosystem to third-party developers to help developers build their own applications based on Wenxin's big model.
By contrast, Huawei is not taking the ordinary path. When releasing Pangu Big Model 3.0, Huawei Cloud publicly stated that the full stack technology of Pangu Big Model was independently innovated by Huawei and did not adopt any open source technology. At the same time, Pangu Big Model will gather countless industry big data, so it will not be open source in the future.
Big parameters are still small and beautiful
In addition, the open source of the Qwen-7B model also brings another consideration: how many parameters do we need for a large model?
It is undeniable that the parameter scale of large models is constantly expanding. Taking OpenAI's GPT big model as an example, GPT-1 only contains 117 million parameters, GPT-3's parameters have reached 175 billion, an increase of over 1000 times in a few years, and GPT-4's parameters have exceeded the trillion level.
The same applies to large domestic models. Baidu Wenxin's big model has 260 billion parameters, Tencent's hybrid model has reached a hundred billion level parameter, Huawei's Pangu's big model parameter scale is estimated to be close to GPT-3.5, and Alibaba's Tongyi's big model has been officially announced to have reached 10 trillion parameters... According to incomplete statistics, there are at least 79 big models in China with a parameter scale of over 1 billion.
Unfortunately, the larger the parameter, the stronger the ability of the larger model. At the World Artificial Intelligence Conference, Wu Yunsheng, Vice President of Tencent Cloud, made a fitting analogy: "Just like athletes practicing physical strength, weightlifters need to lift 200 pounds of barbells, while swimmers need to lift 100 pounds. Different types of athletes don't need everyone to practice 200 pounds of barbells."
As is well known, the higher the parameters of a large model, the more resources and costs it consumes. The vertical large-scale model that deeply cultivates the industry does not need to blindly pursue "large scale" or "high parameters", but should develop relevant model parameters according to customer needs. For example, the BioGPT Large biological model has only 1.5 billion parameters, but its accuracy in biomedical professional testing is better than that of a universal large model with parameters of hundreds of billions.
OpenAI co-founder Sam Altman also publicly stated that OpenAI is approaching the limit of LLM scale, and larger scale does not necessarily mean better models. Parameter scale is no longer an important indicator of model quality.
Wu Di, the head of the Volcano Engine Intelligent Algorithm, also has a similar view. In the long run, reducing costs will become an important factor in the implementation of large model applications. "A well tuned small and medium-sized model may perform as well in specific tasks as a general large model, and the cost may only be one tenth of the original."
At present, almost all domestic technology giants have obtained admission tickets for large models, but the real road choice has just begun.




